ViT-TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文名称:An Image Is Worth 16X16 Words : Transformers For Image Recongition At Scale
作者:Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn,Xiaohua Zhai…
摘要
- 尽管 Transformer 结构在 NLP 领域已经成为主流,但在 CV 领域仍然受到限制。
- 在视觉领域,注意力结构要么和卷积网络一起应用,要么在保证总结构不变的情况下用于替换卷网络中的某些组件。
- 本文表明,这种对于 CNN 的依赖是没有必要的,直接在 transformer 结构中输入一系列图像块(也可以达到非常好的效果。在大量图像上预训练后,在中小型数据集 (ImageNet,CIFAR-100,VTAB…) 上,Vision Transformer(ViT) 仅需少量计算资源,即达到了卷积网络的 SOTA.
相关工作
在图像上应用自注意力需要计算每个像素和其他像素的相关性,而由于像素数量为二次方量级,所以无法使用真实像素大小。因此为了将 Transformer 应用到图像上,之前的工作尝试了几种方式:
- 仅对每个点的局部临域使用注意力机制,而不是计算全局信息,这样的局部多头点积式注意力机制完全可以取代卷积;
- 类似 Sparse Transformer 的工作使用了对全局注意力可缩放的近似值,才能应用在图像上;
- 扩大注意力的另一种方法是将其应用在不同大小的特征块上。
这些专门设计的注意力架构在视觉任务上都取得了不错的结果,但需要进行复杂的工程实现才能在硬件加速器上运行。
方法
受到 NLP 领域 Transformer 的启发,为了将标准的 Transformer 直接应用在图像上,作者将图像分为多个小块 (Patch),将每一个 Patch 当作一个 Linear Embedding,作为 Transformer 的输入,其地位等同于 NLP 领域中的词向量,然后训练一个有监督的图像分类任务。
结构
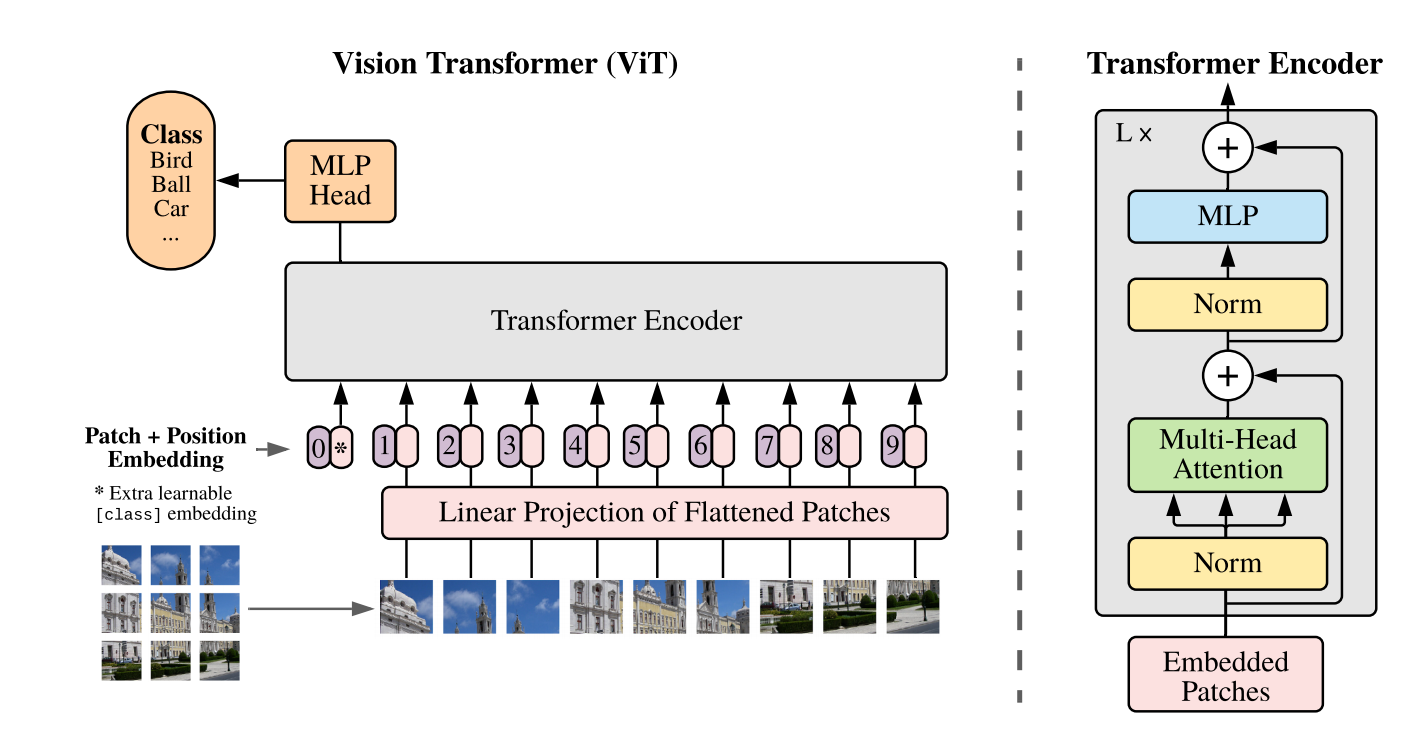
Patch Embedding:
将图片分块这一过程称为 Patch Embedding,这一过程中,将输入 转换为一个 的二维矩阵,其实现方式是通过控制卷积核的大小和步长,来达到一个类似于下采样的效果,代码见 此.
Linear Projection:
类似于 NLP 中的 Word Embedding,这里使用了线性映射来固定输入尺寸,避免 Patch 大小变化而造成的影响
Position Embedding:
同样类似于 NLP 中的 Position Embedding,将图片序列化并重排之后 Transformer 是学习不到位置信息的,因此使用了一维的 Position Embedding,即图中紫色的框。这里没有使用二维的 Position Embedding(即生成两个 1/2 长度的 embedding 分别表示 x、y 位置编码,然后拼接),因为其并没有带来显著的性能提升。
Learnable Embedding:
上图带 * 的粉色框就是 Learnable Embedding.
其作用类似于 BERT 中的 .在 中, 经�过 encoder 后对应的结果作为整个句子的表示;类似地,这里 经过 encoder 后对应的结果也作为整个图的表示。
Transformer Encoder:
与 NLP 中的基本相同,不过在前馈网络中使用了 GeLu(Gaussian Error Linerar Units) 激活函数
GeLu 函数引入了随机正则,公式如下:
其中 表示正态分布,也可使用带参数的正态分布,使用标准正态分布的一种近似公式如下:
:
将 transformer 和 CNN 结合,即将 ResNet 的中间层的 feature map 作为 transformer 的输入。
在这种方案中,作者直接将 ResNet 某一层的 feature map reshape 成 sequence,再通过 Linear Projection 变换维度,然后直接输入进 transformer 中。
缺点
Inductive Bias:Vision Transformer 的图像特定的归纳偏置比 CNN 少得多,在 CNN 中,局�部性、二维领域性和平移等变性贯穿整个模型。而对于 ViT,只有 MLP 层是局部和平移等变的,自注意力是全局的。图像分块之后,所有的空间关系都要从头学习。这也是 Transformer 模型需要巨大数据集的原因。
微调及高分辨率
在大数据集上预训练 ViT,在小数据集上微调。这时,我们删掉预训练的预测头,增加一个初始化为 的 的前向层, 为输出类。与预训练相比,以更高的分辨率进行微调受益更大。当输入高分辨率图像时,保持 patch 尺度不变,那么会有更长的序列长度。Transformer 可以接受动态长度(最大到内存限制),然而预训练时使用的位置 embedding 会失效。因此我们根据其在原图中的位置,对预训练的位置编码进行 2D 插值。
Conclusion
展望未来:
- 将其应用到其他视觉任务中
- 寻找自监督预训练方式
- 进一步扩展提高性能