SkipConvolution
论文名称:Skip-Convolutions for Efficient Video Processing
作者:Amirhossein Habibian, Davide Abati, Taco S. Cohen, Babak Ehteshami Bejnordi
Code:尚未开源
摘要
提出了 Skip-Convlutions 来利用视频流中的大量冗余并节省计算,每个视频都被表示为帧间和网络激活的一系列变化,表示为残差的形式。
为了实现在残差帧上高效地计算,重新构造了标准卷积:
- 每一层都与一个二进制门相结合,决定残差对模型预测是否重要;
- 这些门既可以与卷积核联合训练,也可以根据残差的重要程度(magnitude)跳过残差;
- 门控功能还可以结合块稀疏结构(block-wise sparsity structures),这是在硬件平台上高效实施所必需的。
通过将 EfficientDet 和 HRNet 中的所有卷积替换为 skip-convolution,在两个任务上将计算成本降低了 3 到 4 倍,并且没有任何精度下降。
介绍
视频是一系列静止图像还是一系列连续的变化?
我们通过感知变化来观察世界,并在神经元中累积的差异超过某个阈值时处理信息,这一特性启发了许多神经形态传感器和处理算法,比如基于事件的摄像机(event-based cameras)和脉冲神经网络(spiking neural networks)。
尽管脉冲神经网络在视频处理方面很高效,但其缺乏有效的训练算法,因此并没有像传统算法那样成功。
使用残差帧来表示视频也十分常见,比如在视频压缩编解码器中,这是因为残差帧通常拥有较小的信息熵,因此需要压缩的比特数小。
相关工作
Efficient video models
利用时间冗余是开发高效视频模型的关键,常见的策略是特征传播(feature propagation),它只对关键帧计算主干特征,后续帧直接适应关键帧的主干特征,或者在通过光流、动态滤波器或自注意力的空间对齐之后适应关键帧的特征。
同样地,Skip-Conv 也会传播来自前一帧的特征,然而:
- 特征传播模型取决于对齐步骤,这可能很昂贵,例如用于精确的光流提取;
- 这些方法仅在单个层传播特征,而 Skip-Conv 在每个层传播特征;
- Skip-Conv 有选择地决定是在像素级传播还是计算,而不是整个帧;
- Skip Conv 不需要对原始网络作任何修改。
另一种策略是在连续帧之间穿插交错的深浅骨干(deep and shallow backbone),将在关键帧上提取的深层特征和其他帧上提取的浅层特征进行融合,使用 concatenation、循环神经网络或者是更复杂的动态核蒸馏,这种策略通常会导致关键帧和其他帧之间的精度差距。
另一些工作旨在通过开发更快的 3D 卷积替代方案来实现高效地视频分类,比如 temporal shift modules、2+1D convolutions、神经网络架构搜索或者自适应帧采样。
这些方法主要适用于全局预测任务(可能是指视频分类这种任务),而 Skip-Conv 的目标是流处理任务,例如姿态估计和目标检测,其中每个帧都需要空间密集的预测。
Efficient image models
减少参数冗余(例如通道和层中的参数冗余)是获得高效图像模型的一个基本方面,模型压缩方法,例如低秩张量分解、剪枝、神经网络架构搜索和知识蒸馏等,可以有效地减少任意网络的内存占用和计算成本,Skip-Conv 没有像模型压缩那样利用权重冗余,而是利用激活中的时间冗余。实验证明,这些是互补的,可以结合起来进一步降低计算成本。
条件计算(Conditional computation)最近在开发高效的图像模型方面显示出巨大的潜力,它使模型能够动态调整每个输入的计算图,以跳过处理不必要的分支、层、通道或非重要的空间位置。然而,在图像中很难区分重要区域和非重要区域。Skip-Conv 利用残差帧作为一个强先验,根据它们的变化来识别特征图中的重要区域,通过实验验证,其性能大大优于对应的图像。
Skip Convolutions
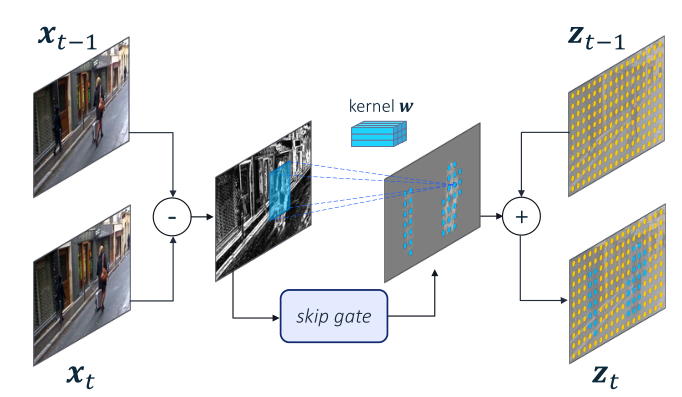
Convolution on Residual Frames
对于一个标准的卷积层,有卷积核 和输入 ,其输出可以定义为:
表示卷积操作, 表示某一时刻的的特征图
众所周知,卷积是一个线性函数,因此我们可以将输出写为:
即表示残差帧,对于第一帧来说 。
由于视频中连续帧多是高度相关的,因此残差帧通常是稀疏的,如下图所示:

这种稀疏性可以有效地提高网络效率,对于残差帧中 0 值的部分,其经过卷积的输出依然是 0,因此可以直��接跳过(skip)。
注意到上图有许多很细小的非 0 区域(可能是摄像时的光影变化等),这些细小的噪声一定程度上会阻止 skip-conv 跳过,为了解决这个问题,为每一层 skip-conv 都引入了一个门控函数 ,为输入特征图预测一个二进制 mask 来过滤细小的部分,如此,skip-conv 被定义为:
符号表示 是 的一个近似, 表示逐元素相乘。
Skipping Non-zero Residuals
提出了两个门控函数:
- Norm gate:如果残差的残差的范数足够小则选择跳过,norm gate 没有任何可训练的参数;
- Gumbel gate:其参数和卷积核联合训练。
Norm gate
Norm gate 可以定义为:
但是这样就需要对每个像素进行卷积,因此提出了一个近似函数:
该式被称为 Input-Norm gate,这里使用局部卷积操作来代替逐像素计算,具体来说就是对 取绝对值,在领域内求和,相当于上式中的 p=1
除此之外,考虑了另一种更准确的近似函数,由杨氏不等式可以得到卷积范数的上界:
通过上式可得:
该式被称为 Output-Norm gate,其中卷积核的范数在所有的四个维度上计算,将 Input-Nrom gate 和 Output-Norm gate 的 p 设置为 1,所有层共享一致的 。
Gumbel gate
残差帧范数表示帧间发生显著变化的区域,然而并非所有的变化都对最终预测同样重要,比如背景的变化,这一观察结果表明,通过在门控函数内引入一些可训练的参数,可以获得更高的效率,在不影响模型性能的情况下,甚至可以跳过较大的残差。
Gumbel gate 使用与对应层参数完全相同的卷积核,输出通道为 1,之后使用 sigmoid 函数获取像素级别的伯努利分布,训练期间从伯努利分布中抽取二元决策样本,在推理时则进行取整:
采用 Gumbel 重新参数化和直通梯度估计器,以便采样过程进行反向传播。通过最小化 ,使得门控参数与所有模型参数共同学习。超参数 平衡了 测量的模型精度与 测量的模型效率。我们将门控 loss 定义为处理 T 个连续帧所需的平均乘法累积(MAC):
乘积累加运算的操作是将乘法的乘积结果和累加器 A 的值相加,再存入累加器。 L 是网络中的层数, 表示空间位置上的平均值,系数 表示第 l 和卷积层的 MAC 的数量(这里可能是为了一定程度上限制门控函数进行过多的运算了,来达到提高效率的作用)。与递归网络类似,在固定长度的帧序列上训练模型,并对任意数量的帧进行迭代推理。
Structured Sparsity
与稀疏卷积类似,Skip-Conv 的有效实现需要特征图中的块结构稀疏性(block-wise structured sparsity),主要原因有两个:
- 利用块结构可以减少输入和输出张量的收集和分散所涉及的内存开销;
- 此外,许多硬件平台在小 patch(例如 8×8)上分布执行卷积。
通过简单地在门控函数添加下采样和上采样函数,可以扩展 SkipConv 以生成结构化稀疏性。具体来说,作者添加了一个最大池层,kernel size 和 stride 为 b,接一个最近邻上采样,其比例因子为 b。这使得预测的门具有 b×b 结构,如下图所示:

尽管分辨率显著降低,但消融实验证明与非结构化门控相比并不会损失性能,因此,结构化稀疏性是对性能影响最小的情况下实现更高效的关键。
Runtime speed up
通过研究 MAC 数量的减少来衡量理论加速是如何转化为实际加速的,作者使用了基于 im2col 的稀疏卷积实现,im2col 将卷积运算转换为两个矩阵的矩阵乘法,对于稀疏卷积,乘法只在非稀疏列进行,其他列中直接填 0。使用 HRNet-w32 在 CPU 上进行实验,结果如下:
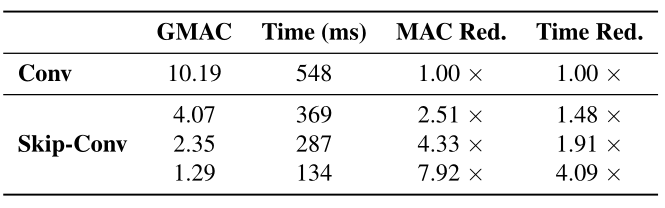
实际运行的速度提升约为理论速度提升的一半(理论速度提升即为 MAC 的减小量),这是因为 MAC 不计入稀疏卷积核的内存开销,并且实际运行速度和理论速度可以通过高度优化的 CUDA 进一步缩小。
思考
本文的 idea 确实是很简单,只处理帧与帧之间的相差的部分,但是对于视频来说,不同时刻的光影等都会造成这种相差,因此提出了门控函数来选取真正重要的部分,另一方面注意到残差帧的稀疏性,提出了结构化稀疏和使用稀疏卷积进一步提高效率,此外还提出了新的 loss 通过计算数量来约束模型的轻量化。
但是 skip-conv 的缺点�也是显而易见的,当摄像机剧烈晃动或者背景变化剧烈时,其表现应该不会很好(或许会退化为标准卷积?),为了应对这一点显然需要更多的工作,或许训练时增加足够的数据增强可以一定程度上得到缓解,文章末尾也提到将 Skip-Conv 与可学习的翘曲函数(learnable warping functions)相结合可能会有助于补偿相机的剧烈运动,但这是以后的工作了。