循环神经网络
为什么需要RNN
在深度学习兴起之前,NLP 领域一直都是统计模型的天下,最常用的模型如 n-gram,但是其难以捕捉中长距离信息,Bengio 团队将 N-GRAM 融入前馈神经网络中,但是提升有限。
在 NLP 中,输入的数据是一段段 序列,而序列中的信息存在着相互关系,显然,输入与输出独立的全连接层已然不能胜任 NLP 的各种任务。我们需要一种能够正确建模序列关系的网络,RNN 便由此应运而生。
基础结构
对于一个序列

最常见的序列有一段音乐、一句话、一段视频等
RNN的基础结构为
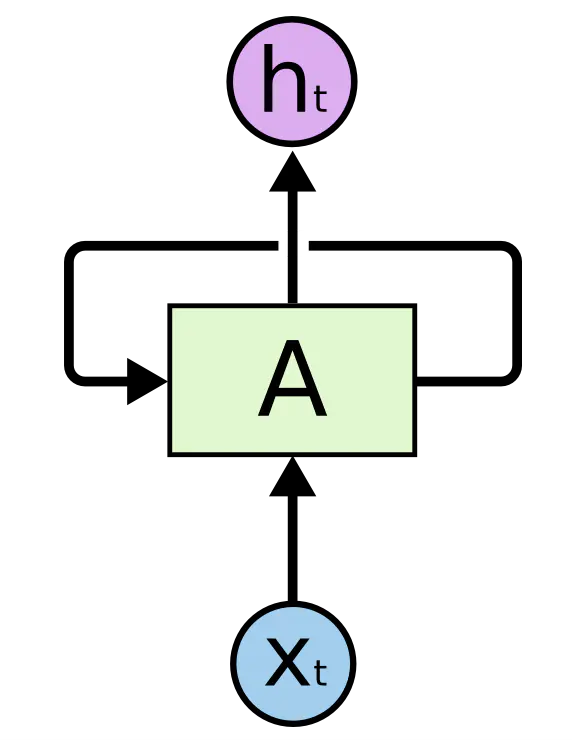
A 接收序列的某一个 ,输出一个 ,这个 被称为隐状态(Hidden State),他会与下一步的输入 共同输入 A,以此来建模序列关系。
这是一种自回归模型(AR),前一步的预测会添加到下一步当中,因此其只能单独注意下文或者上文的信息
为了更直观的理解 RNN,对于一段序列和某个神经元 A,按照 的顺序输入其中的数据,可以展开成下图右侧的形式
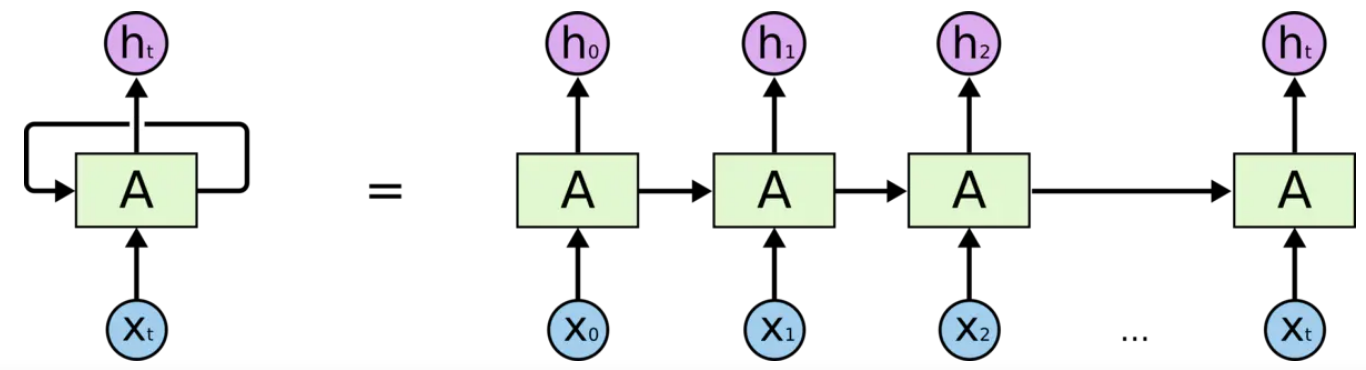
需要注意的是:这里的 A 是相同的 A,也就是说,整个 RNN 的各个步骤都是参数共享的
隐状态
让我们简化神经元的图片,去除其中的 A
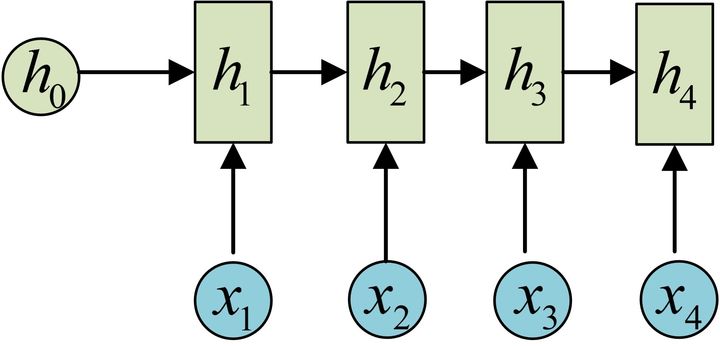
的计算公式如下,其中的 依旧是共享的
这里的 是激活函数,一般 RNN 使用 ,降低了梯度爆炸的风险
输出
接下来让我们看看 RNN 的输出是怎样的
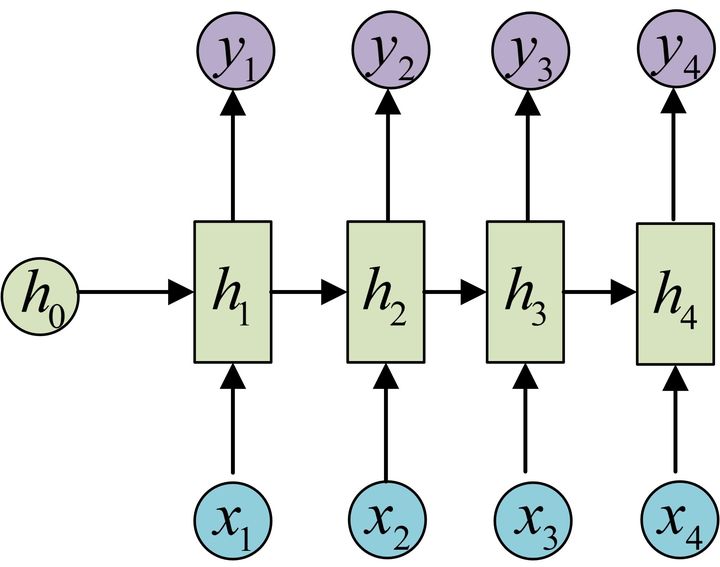
通过 来得到对应的 ,具体公式为
从这里我们可以看到标准 RNN 的一个限制——输入与输出是等长的
反向传播
由于 RNN 中的数据相互牵连,序列当中在后面的数据得到的输出与前面所有的数据都有关系,求解梯度时使用链式法则得到的公式将会异常的长
并且其中经常使用 激活函数,其导数的大小始终小于等于1��,由此可得:
对于较长的序列,RNN 很容易出现梯度消失的情况(有观点认为 RNN 的梯度消失和普通网络的不同:它的梯度被近距离梯度主导,被远距离梯度忽略)
因此 RNN 采用一种特殊的方法 BPTT 进行训练,将网络结构分组,对每组计算 loss
另外,当其中的其他导数过大的时,也很容易出现梯度爆炸的情况
因此虽然理论上 RNN 可以很好的处理长距离信息的关系,但是实际情况并不好
另外在这里稍微提一点:
NLP 任务的归一化使用 而不是 ,因为在批次上进行归一化会混乱不同语句之间的信息,我们需要在每个语句之中进行归一化。
不等长问题
并不是所有任务都会要求输入和输出等长,因此有许多种不同类型的 RNN 来解决输入输出不等长的问题
N-1
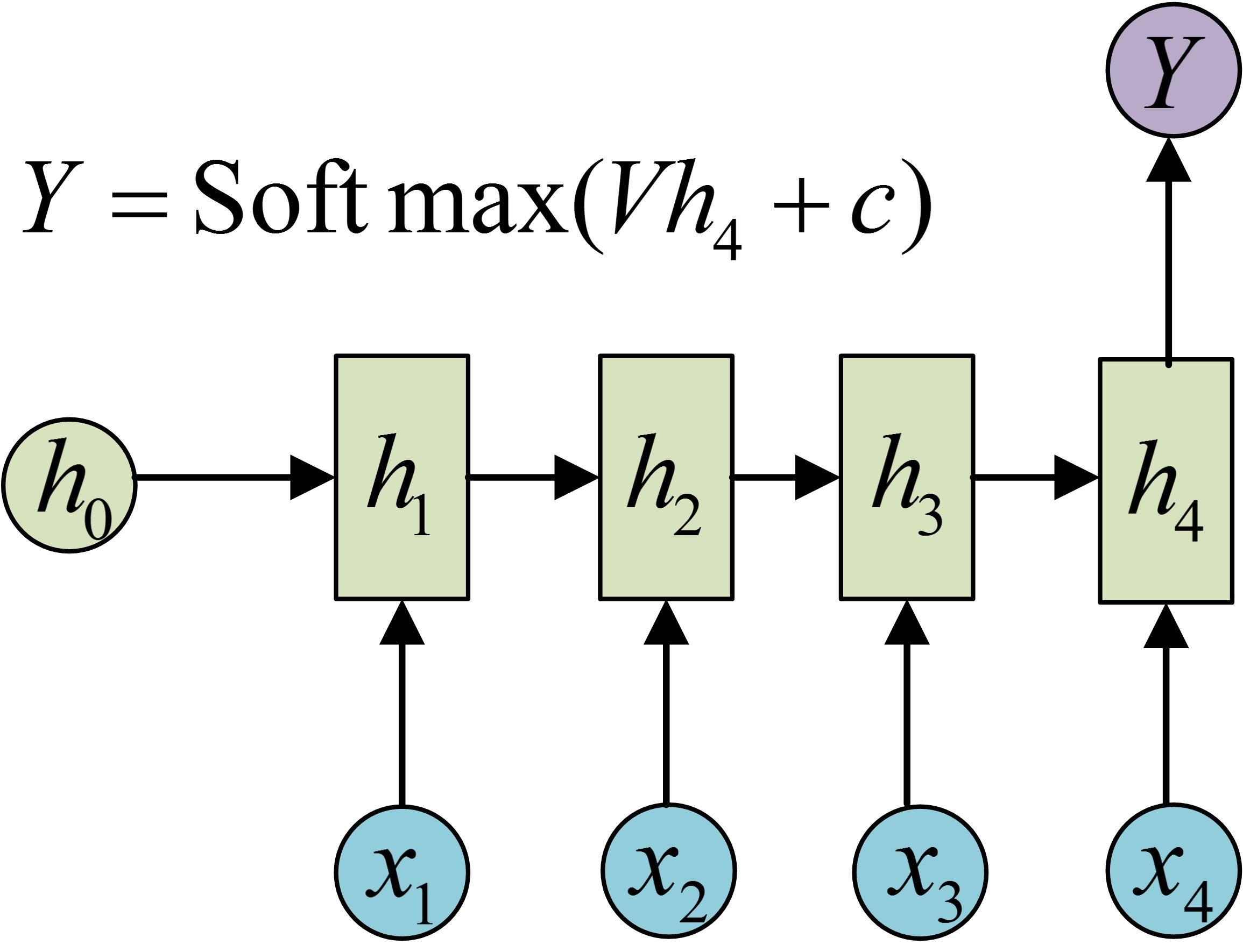
只取最后一层来得到输出
或者是利用每一层的输出后接一个 softmax 来进行分类等
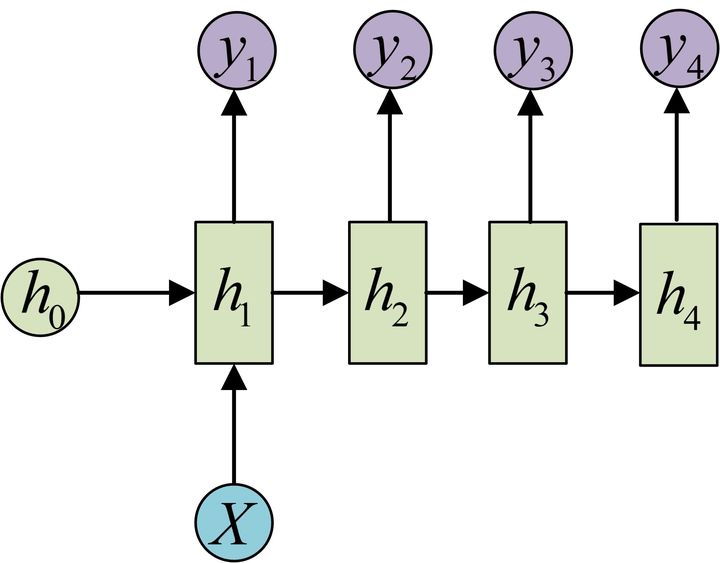
1-N
主要有两种方法
x 仅作为最开始的输入:
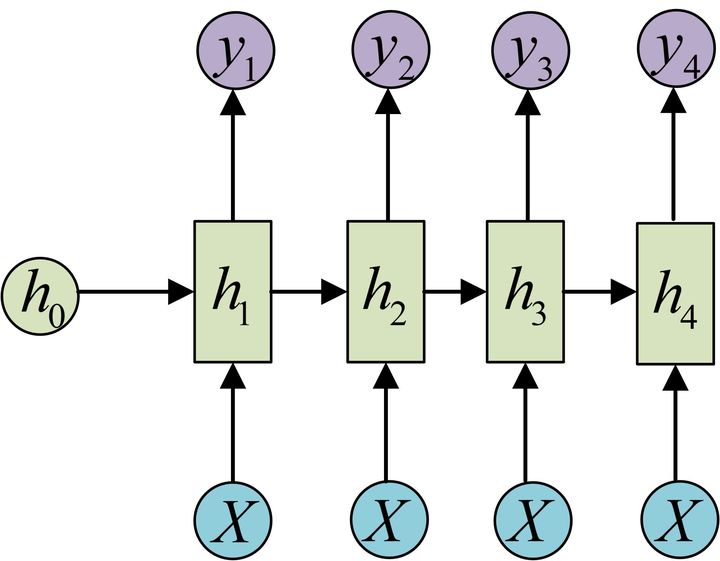
X 作为每层的输入:
N-M
Encoder-Decoder 的结构,首先得到一个编码 c,解码时有两种方法
其实就是相当于 N-1 和 1-M 两个 RNN 的拼接
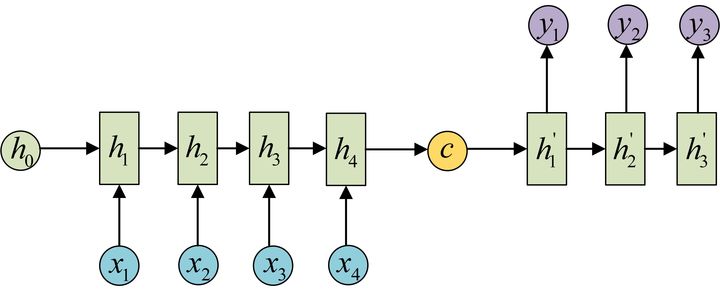
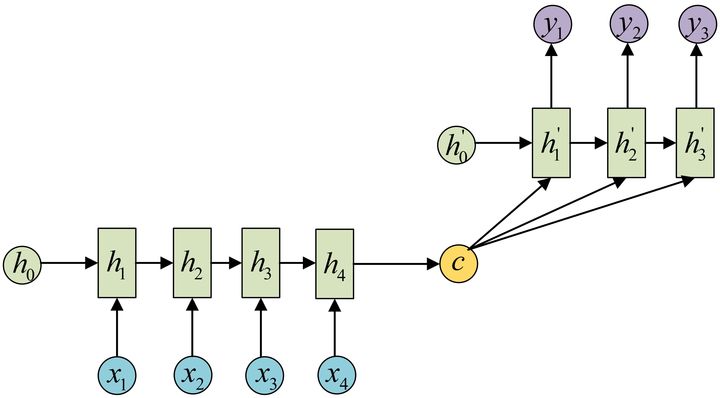
其损失函数定义为
RNN的变体
Bi-directional Recurrent Neural Network
RNN 总是在学习序列某个点之前的信息,想象一下,在学习的同时将该点之后的信息加入会怎样?
网路将学习到更多的上下文(未来)信息,来得到更好的效果
值得注意的是,不能加入过多的下文(未来)信息,因为这会占用网络过多的资源,从而导致效果下降
网路的构建由两个反向的 RNN 组成
长短期记忆网络
相对于长距离(长期)记忆,RNN 更擅长于短距离(短期)记忆,因此提出了 LSTM 来提升网络在长序列中的建模效果
LSTM 可以看作一种特殊的 RNN,他们都拥有 Hidden State 和循环的形式,只是 LSTM 引入了输入门、输出门和遗忘门,用来控制信息的流动,从而解决了长距离信息建模的问题
获得长距离(长期)信息实际上是 LSTM 的一种“天赋”,并不需要付出很大的代价
基本结构
在介绍其结构之前先让我们认识一下各种图标表示的含义

- 黄色方框表示一层网络
- 粉色原点表示进行按位操作
其基�本结构为:
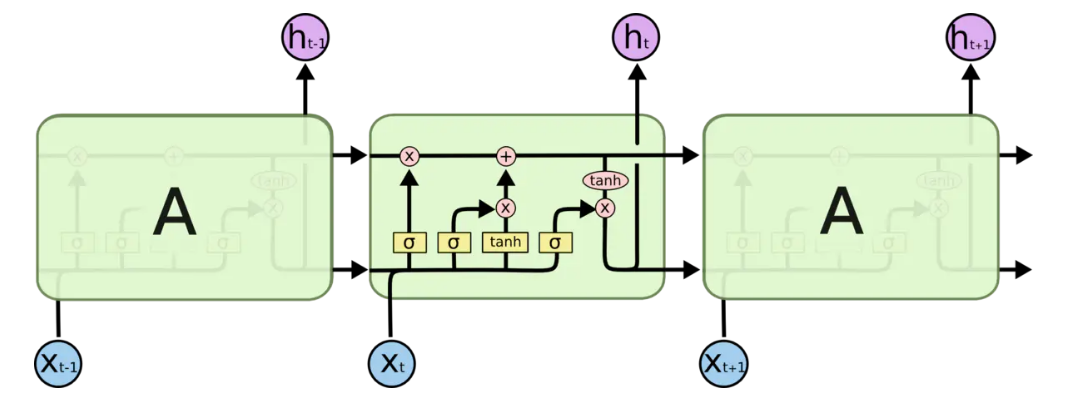
忽略内部的信息,其结构与 RNN 十分类似,标准的 LSTM 便是完全由这样的一个结构组成
将RNN的结构图绘制成相似的结构图
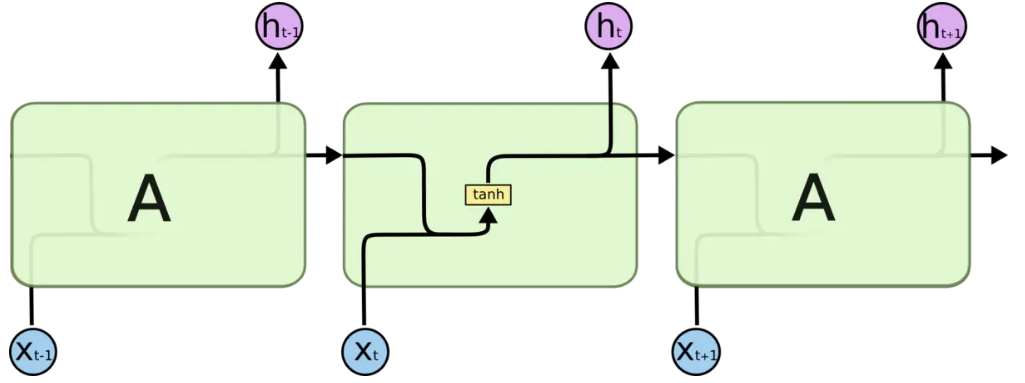
接下来让我们逐步分解剖析其中的具体结构
细胞状态
细胞状态(Cell State)是 LSTM 单独提出的一个概念,用来改善长距离的建模效果
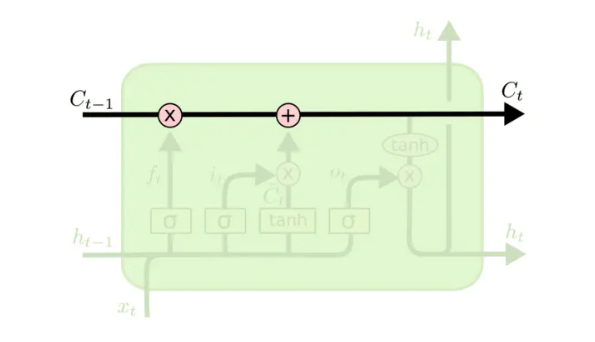
从图中可以看出,此结构类似一个传送带,如果将整个网络的结构图都画出来,就会发现这条“传送带”贯穿始终
个人理解,Cell State 包含长期记忆,而 Hidden State 是选择性地输出 Cell State 的内容
门控
门控可以控制信息的流动情况,在 LSTM 中,三个门控主要用来增减信息来达到保护和控制细胞状态的作用
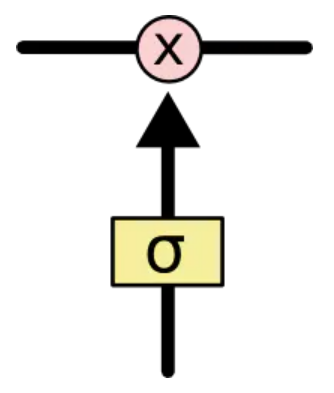
这里的 是 函数,它会输出一个0-1之间的值,以此控制信息的流动
遗忘门
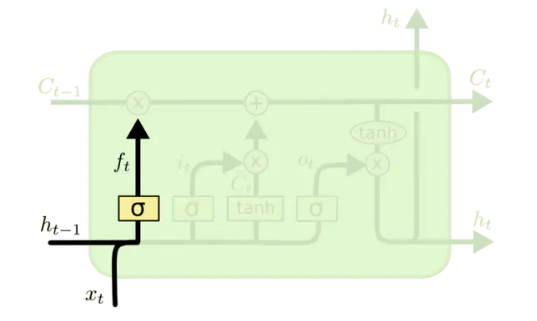
按照人脑的记忆机制添加了遗忘门,遗忘门会读取 ,并得到一个0-1之间的权重,它将被乘在细胞状态上,表示应该忘记多少信息,其公式为
个人认为更直观的解释是还要记住前面的多少信息
输入门
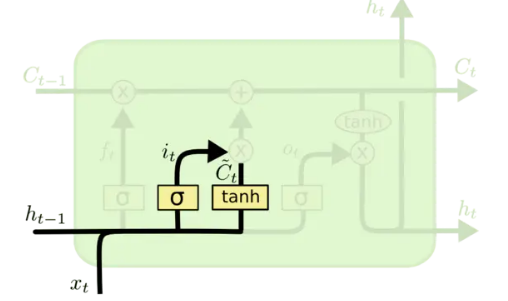
输入门用于更新细胞状态
用来控制多少信息要被更新到细胞状态
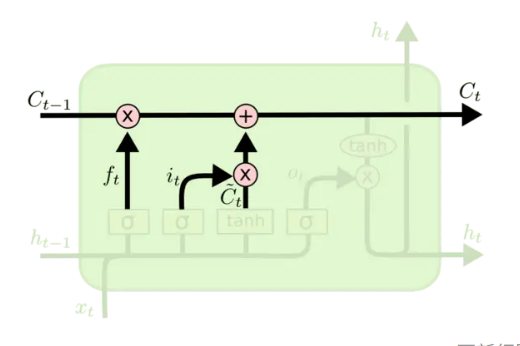
更新的公式为
输出层
输出层决定了要输出的
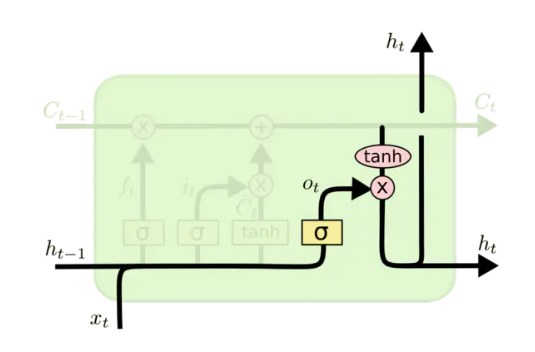
公式为
通过细胞状态和上层的输入来决定输出
LSTM如何解决梯度消失
LSTM的变体
门控循环单元
GRU 是 LSTM 的一种变体,很多情况下,它们的表现相差无几,但是 GRU 更易于计算, 参数量约为 RNN 的三倍
GRU 组合了遗忘门和输入门到一个单独的“更新门”中,同时合并了 cell state 和 hidden state
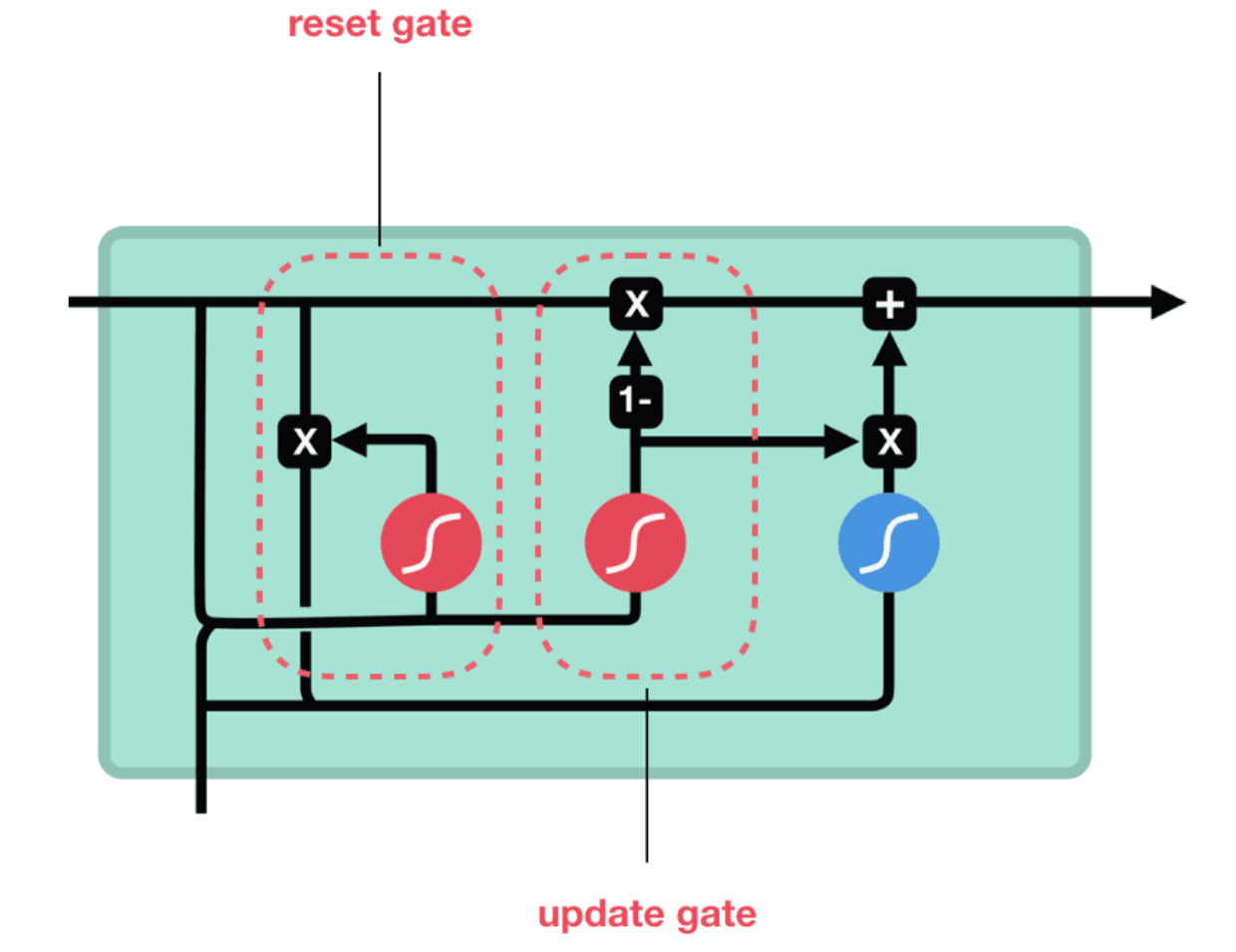
最上方的一条横线代表着 Hidden State,左下角的输入为
重置门:用来决定要丢弃哪些信息
更新门:的作用类似于 LSTM 的遗忘和输入门,它决定着哪些信息将要被添加或者丢弃
输出: