Group Relative Policy Optimization
群体相对策略优化
Workflow
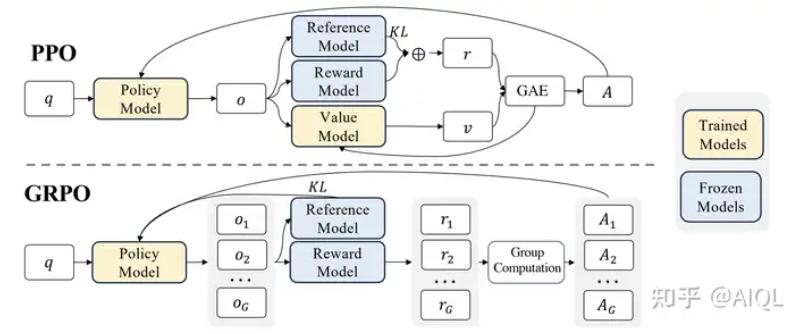
- 对于每个 prompt,采样一组回答 G;
- 计算每个回答的奖励;
- 对每个回答计算组内标准化的 advatange,Ai=std(G)Rϕ(ri)−mean(G)。
如此一来便去除了之前需要在每一步生成上计算价值函数,并且直接去除了价值函数。
Objective
与 PPO 类似,GRPO 仍然使用了剪切的代理损失(clipped surrogate loss)以及 KL 散度惩罚(KL penalty)。这里没有使用熵奖励项,因为基于分组的采样本身已经鼓励了探索性。剪切的代理损失与 PPO 中使用的完全相同,但为了完整性,这里再说明一下
Lclip(θ)=N1i=1∑N(min(πθold(ri∣p)πθ(ri∣p)Ai, clip(πθold(ri∣p)πθ(ri∣p),1−ϵ,1+ϵ)Ai))
总的 loss 为
LGRPO(θ)=Maximise rewardLclip(θ)−Penalise KL divergencew1DKL(πθ∣∣πorig)