VOLO
论文名称:VOLO: Vision Outlooker for Visual Recognition
作者:Li Yuan, Qibin Hou, Zihang Jiang, Jiashi Feng, Shuicheng Yan
摘要
- 视觉识别任务已被 主宰多年。基于自注意力的 在 分类方面表现出了极大的潜力,在没有额外数据前提下, 的性能与最先进的 模型仍具有差距。在这项工作中,我们的目标是缩小这两者之间的性能差距,并且证明了基于注意力的模型确实能够比 表现更好。
- 与此同时,我们发现限制 在 分类中的性能的主要因素是其在将细粒度级别的特征编码乘 表示过程中比较低效,为了解决这个问题,我们引入了一种新的 注意力,并提出了一个简单而通用的架构,称为 ()。 注意力主要将 - 级别的特征和上下文信息更高效地编码到 表示中,这些 对识别性能至关重要,但往往被自注意力所忽视。
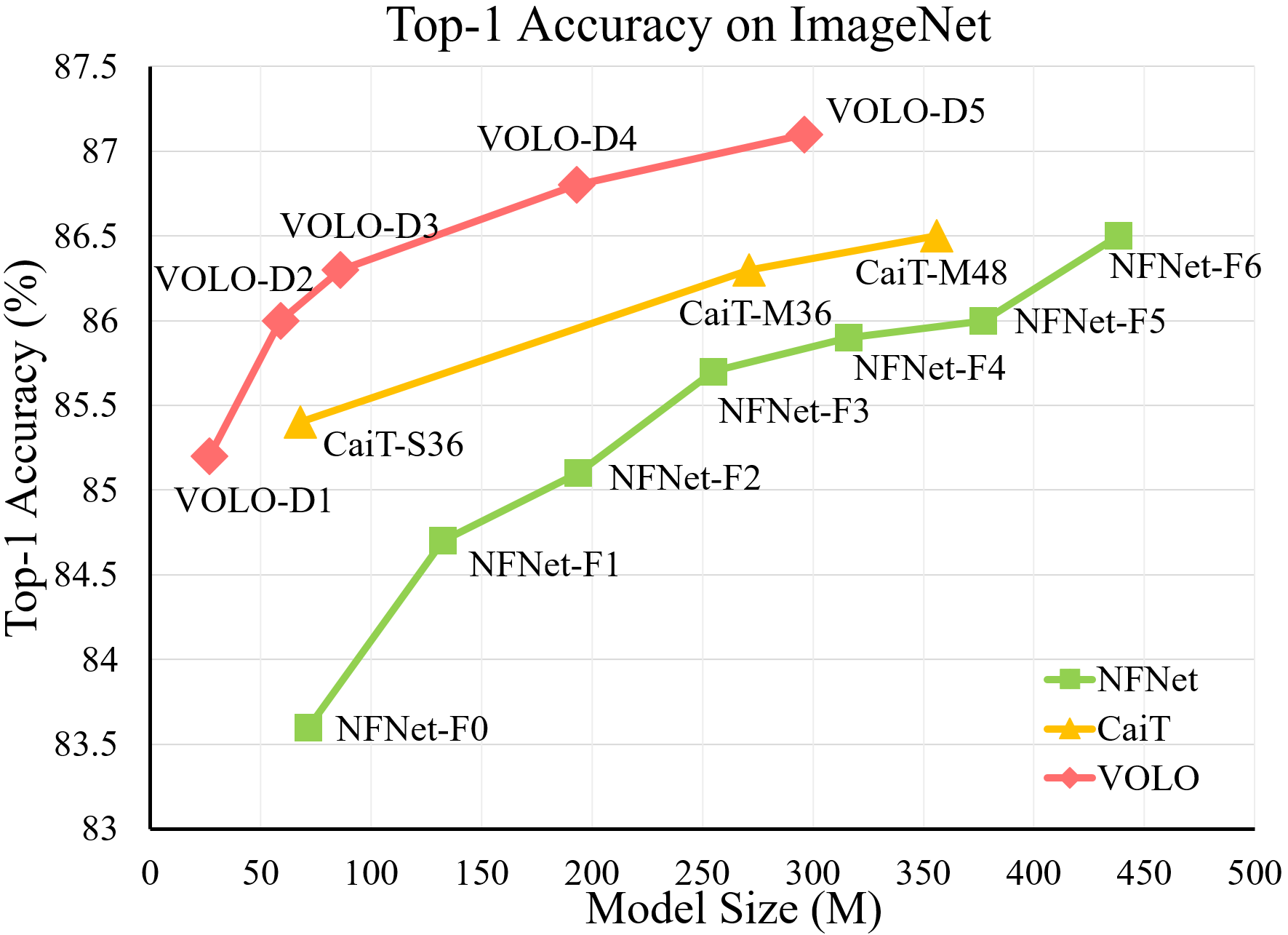
- 实验表明,在不使用任何额外训练数据的情况下, 在 - 分类任务上达到了 87.1% 的 - 准确率,这是第一个超过 87% 的模型。此外,预训练好的 VOLO 模型还可以很好地迁移到下游任务,如语义分割。我们在 验证集上获得了 84.3% ,在 验证集上获得了 54.3% 的 ,均创下了最新记录。
总结:本文提出了一种新型的注意力机制——,与粗略建模全局长距离关系的 不同, 能在邻域上更精细地编码领域特征,弥补了 对更精细特征编码的不足。
OutLooker Attention
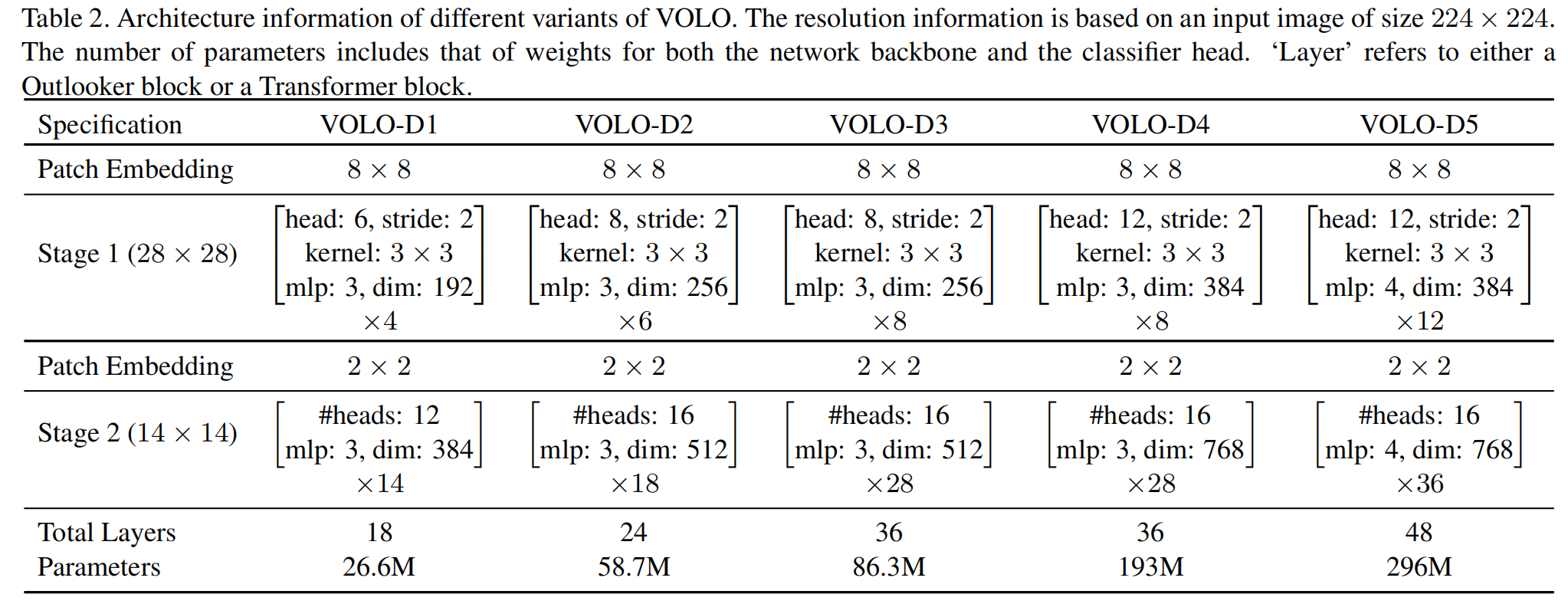
OutLooker模块可视作拥有两个独立阶段的结构,第一个部分包含一堆 用于生成精细化的表示( ),第二个部分部署一系列的转换器来聚合全局信息。在每个部分之前,都有块嵌入模块( )将输入映射到指定形状。
理论和形式
OutLooker 的提出主要基于以下两点:
- 每个空间位置的特征都具有足够的代表性,可以生成聚集了局部邻近信��息的注意力权重
- 密集的局部空间聚合信息可以有效地编码精细层次的信息
OutLooker 由用于空间信息编码的 outlook 注意层和用于通道信息交互的 MLP 组成,给定 ,有一下形式:
其中 表示
方法

从上图我们可以很容易得到,整个过程分为两条路线,接下来先介绍第一条

Outlook Attention Generation:
- 通过全连接层将 的通道由 变为 ,得到
- 通过 将注意力权重变为 ,表示每个像素生成的权重
- 在最后一维使用 ,这里可以看出为什么通道数变为 ,因为其需要为 大小的窗口里所有的像素建立相互关系,也就是说,这可以看作是一种局部的 ,这也是与 等类似工作的一个巨大不同之处;这里的 就是对每一个像素计算与其他所有像��素(包括自己)的一个相似度
Dense aggregation(Value Generation):
- 首先使用全连接层进行一次线性变换,通道数不改变
- 使用
nn.Unfold()进行展开,维度为 ,得到
Calculate The Attention:
- 两条路线得到的矩阵进行矩阵乘积,相当进行了一次卷积操作,卷积核为
- 使用
nn.Fold折叠回�原尺寸
整个过程的代码如下所示:

class OutlookAttention(nn.Module):
"""
Implementation of outlook attention
--dim: hidden dim
--num_heads: number of heads
--kernel_size: kernel size in each window for outlook attention
return: token features after outlook attention
"""
def __init__(self, dim, num_heads, kernel_size=3, padding=1, stride=1,
qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
head_dim = dim // num_heads
self.num_heads = num_heads
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.scale = qk_scale or head_dim**-0.5
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn = nn.Linear(dim, kernel_size**4 * num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.unfold = nn.Unfold(kernel_size=kernel_size, padding=padding, stride=stride)
self.pool = nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True) # stride的实现可能靠pool
def forward(self, x):
B, H, W, C = x.shape
v = self.v(x).permute(0, 3, 1, 2) # B, H, W, C ->B, C, H, w
h, w = math.ceil(H / self.stride), math.ceil(W / self.stride)
v = self.unfold(v).reshape(B, self.num_heads, C // self.num_heads,
self.kernel_size * self.kernel_size,
h * w).permute(0, 1, 4, 3, 2) # B, N, C//N, K*K, H*W->B, N, H*W, K*K, C//N
attn = self.pool(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
attn = self.attn(attn).reshape(
B, h * w, self.num_heads, self.kernel_size * self.kernel_size,
self.kernel_size * self.kernel_size).permute(0, 2, 1, 3, 4) # B,H,N,kxk,kxk
attn = attn * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).permute(0, 1, 4, 3, 2).reshape(
B, C * self.kernel_size * self.kernel_size, h * w)
x = F.fold(x, output_size=(H, W), kernel_size=self.kernel_size,
padding=self.padding, stride=self.stride)
x = self.proj(x.permute(0, 2, 3, 1))
x = self.proj_drop(x)
return x
多头机制的实现
多头机制的实现十分简单,假设设置头数为 ,只需要调整 ,最��后生成 个 ,其中 ,分别计算最后 Concat 起来
Patch Embedding
Patch Embedding 最初应该是源于 ViT,类似于池化,通过卷积的线性变换将特征图中的一小块(patch)进行映射,最终实现一种下采样的效果
不同与池化的粗暴,Patch Embedding 能一定程度上保留信息,扩大感受野
同时,可以减少后续模块的计算量
其实现方法通过控制卷积核大小和步长来实现,VOLO 实现的代码如下
class PatchEmbed(nn.Module):
"""
Image to Patch Embedding.
Different with ViT use 1 conv layer, we use 4 conv layers to do patch embedding
"""
def __init__(self, img_size=224, stem_conv=False, stem_stride=1,
patch_size=8, in_chans=3, hidden_dim=64, embed_dim=384):
super().__init__()
assert patch_size in [4, 8, 16]
self.stem_conv = stem_conv
if stem_conv:
self.conv = nn.Sequential(
nn.Conv2d(in_chans, hidden_dim, kernel_size=7, stride=stem_stride,
padding=3, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=1,
padding=1, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=1,
padding=1, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
)
self.proj = nn.Conv2d(hidden_dim,
embed_dim,
kernel_size=patch_size // stem_stride,
stride=patch_size // stem_stride)
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
def forward(self, x):
if self.stem_conv:
x = self.conv(x)
x = self.proj(x) # B, C, H, W
return x
不同与 ViT 使用一层卷积进行嵌入,本文使用四层,前三层提取一定的特征,最后一层将整张 feature map 分为 patch_size 个部分,形状变为
在此起着关键的作用,其不但降低了注意力模块所需的计算量,其次,能够在一定程度上起到聚合临近信息的作用,因为 的生成�是仅仅在通道上使用线性转换,其感受野实际上为 , 使得感受野大大增加,虽然 只是注意中心像素几个邻近像素,但是其在原图上的感受野十分大。
当然,在 中也得到了局部邻近信息的聚合。
网络结构
Attention

在 中,Q,K,V 都是输入本身的线性变换
在 中,Q 为输入本身的线性变换,而 K 和 V 是引入的参数
在 中,Q 为输入本身,V 为输入本身的线性变换,而 K 是引入的参数
其他
实际上这篇论文与 Involution: Inverting the Inherence of Convolution for Visual Recognition 十分相似,在Involution一文中,提出了更为广泛的方法,本文可以看作是 Involution 的一种实例
对于这个情况,作者是如此回应的:
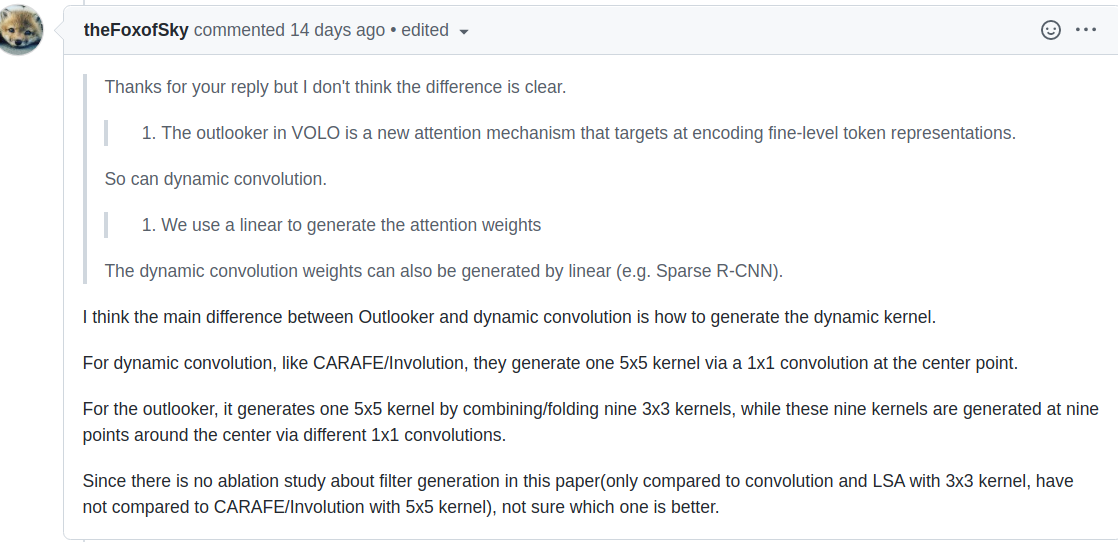
也就是上文所说的 的原因
两篇文章的不同之处在于 将这种方法视为一种新型的卷积,而本文则是视其为一种注意力模块,实际上二者存在着某些异曲同工之妙,譬如本文中的多头机制则对应着 中的分组 (并不完全相同)
不同之处又在于,本文学习了 的 方法,减少了注意力模块中的计算量,并且改善了“卷积核”的生成仅与中心像素有关的情况(或许通过不断学习,卷积核能够建模中心像素与临近像素的关系)。