极化自注意力
论文名称:Polarized Self-Attention: Towards High-quality Pixel-wise Regression
作者:Huajun Liu, Fuqiang Liu, Xinyi Fan
摘要
细粒度的像素级任务(比如语义分割)一直都是计算机视觉中非常重要的任务。不同于分类或者检测,细粒度的像素级任务要求模型在低计算开销下,能够建模高分辨率输入/输出特征的长距离依赖关系,进而来估计高度非线性的像素语义。中的注意力机制能够捕获长距离的依赖关系,但是这种方式十分复杂且对噪声敏感。
本文提出了即插即用的极化自注意力模块,该模块包含两个关键设计,以保证高质量的像素回归:
- 极化滤波():在通道和空间维度保持比较高的分辨率(在通道上保持 的维度,在空间上保持 的维度 ),进一步减少低分辨率、低通��道数和上采样造成的信息损失。
- 增强():采用细粒度回归输出分布的非线性函数。
相关工作
逐像素回归任务
用于像素回归的 的进展基本上都是追求更高的分辨率,目前有相当多的网络挑战如何保持图像的高分辨率,研究人员也越�来越认识到高分辨率信息的重要性,将从注意力的角度进一步追求上述努力的高分辨率目标,并进一步推动 的发展。基于双重注意力机制,本文针对 的任务,提出了一种更加精细的双重注意力机制——极化自注意力
自注意力机制
注意力机制已经被引入到许多视觉任务中,以弥补标准卷积的缺点。自注意力在序列建模和生成性建模任务中获得成功后,已经成为捕获长距离关系的标准模块。已有工作证明,拥有足够数量头的多头自注意力层可以至少与任何卷积层具有相同的表现力。 促进了逐像素回归的自注意力。
方法

上图显示了一些注意力模块在通道和空间维度上的分辨率和时间复杂度,可以看到,在通道和空间维度的分辨率很高,但是其时间复杂度也很高;剩下的模块虽然计算量较小,但是很难做到保持高分辨率。
而本文提出的 可以在保持高分辨率的情况下,实现较低的时间复杂度
Polarized Self-Attention (PSA) Block
作者在 中采用了一种极化滤波()的机制。类似于光学透镜过滤光一样,每个 的作用都是用于增强或者削弱特征。(在摄影时,所有横向的光都会进行反射和折射。极化滤波的作用就是只允许正交于横向方向的光通过,以此来提高照片的对比度。 由于在滤波过程中,总强度会损失,所以滤波后的光通常动态范围较小,因此需要额外的提升,用来恢复原始场景的详细信息。)
其实就是编故事(X),简而言之,模块分别在空间和通道维度上进行注意力的计算,其结构如下所示,有两种排列方式:
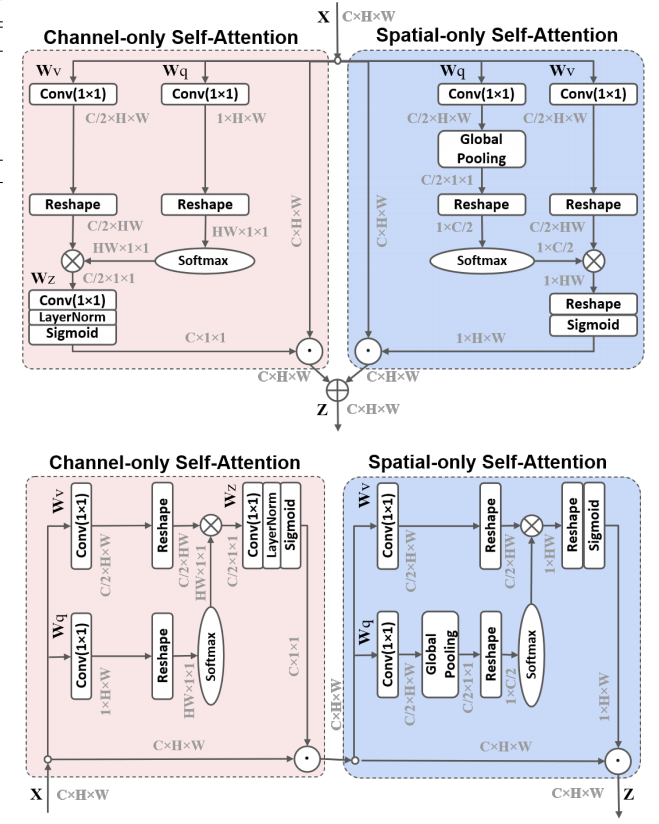
在进一步介绍模块结构前,先了解一下各个符号的含义:
表示输入,表示 卷积,表示 操作,表示 ,表示层归一化,,这其中 表示 的第 个通道上的特征图,也就是在通道维度上进行 ,表示全局平均池化。
Channel-only branch
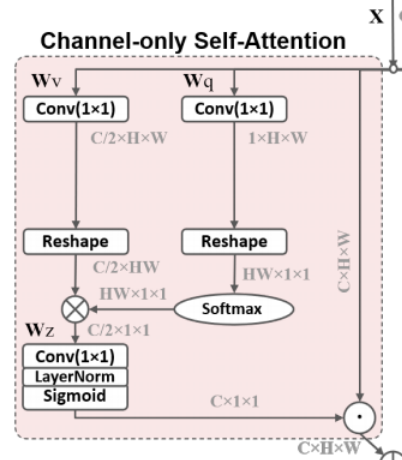
通道注意力可以表示为:
其主要流程为:
-
生成 并计算相似度:通过 卷积降低通道数至 ,使用 操作代替 ,与通道注意力的全局平均池化降低了大量分辨率不同,这里的 给出了空间维度上各个像素点的相对重要性(并不能称之为相似度吧)并且起到一种归一化的作用。
-
生成 :通过 卷积降低通道数至 ,使用 操作方便与相似度进行矩阵乘法,同时聚集了各个通道上的信息,也就是说这里在每个通道上保持高分辨率的同时完成了注意力的计算,具体演示如下:
的每一行都代表着每一个通道上的空间信息,与 进行加权。
-
得到通道注意力:使用 卷积降维,进行归一化,负责最后激活,最终得到一个 的通道注意力权重。
可能的代码:
class ChannelAttention(nn.Module):
def __init__(self, in_ch):
super(ChannelAttention).__init__()
self.wq = nn.Conv2d(in_ch, 1, 1)
self.wv = nn.Conv2d(in_ch, in_ch//2, 1)
self.softmax = nn.Softmax(dim=1)
self.wz = nn.Conv2d(in_ch//2, in_ch, 1)
self.ln = nn.LayerNrom(in_ch)
def forward(self, x):
b, c, h, w = x.size()
q = self.wq(x).reshape(b, h*w, 1, 1)
v = self.wv(x).reshape(b, c//2, -1)
z = self.wz(torch.matmul(v, self.softmax(q))
out=torch.sigmoid(nn.ln(z))
return out
其实这和空间注意力的计算有某些相似之处:
- 空间注意力一般在通道维度上进行最大或者平均池化,在这里使用了 的卷积来聚集信息;
- 这里的第二步相当于空间注意力的加权,一般来说,空间注意力在此就已经完成了;
- 在加权之后,通过一个空间维度上的求和,来获取每一个通道的权重。
因此,我们可以写一个类似的代码,更充分的利用空间上的信息来获得通道注意力:
class Channel_Attention_With_Spatial(nn.Module):
def __init__(self):
self.conv = nn.Conv2d(2, 1, kernel_size=7, padding=3, bias=false)
super(Channel_Attention_With_Spatial, self).__init__()
def forward(self, x):
b = x.shape[0]
ave = torch.mean(x, dim=1, keepdim=True)
m, _ = torch.max(x, dim=1, keepdim=True)
weight = torch.sigmoid(self.conv(torch.cat([ave, m], dim=1)))
atten = (x*weight).sum(axis=[2, 3], keepdim=True)
return atten*x
Spatial-only branch
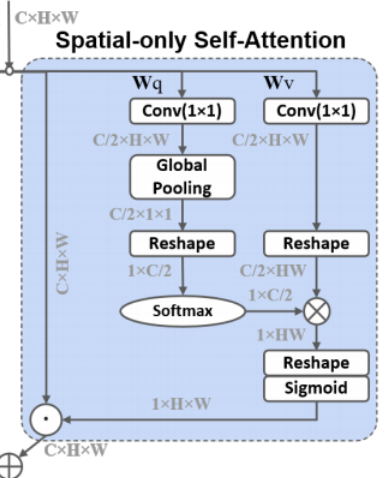
空间注意力可以表示为:
其主要流程为:
-
生成 并计算相似度:通过 的卷积降低通道数至 ,使用全局平均池化聚集信息,使用 代替 ,在最后一维使用 求解相似度;
-
生成 :通过 卷积降低通道数至 ,使用 操作方便与相似度进行矩阵乘法;其计算了每个像素点通道上的注意力,如下图:
的每一列都代表着某个像素点上所有通道的信息,与 进行加权。
-
得到空间注意力: 并使用 进行最后的激活,最终得到一个 的空间注意力权重。
可能的代码:
class SpatialAttention(nn.Module):
def __init__(self, in_ch):
super(SpatialAttention).__init__()
self.wq=nn.Conv2d(in_ch, in_ch//2, 1)
self.wv=nn.Conv2d(in_ch, in_ch//2, 1)
self.gp=nn.AdaptiveAvgPool2d((1, 1))
self.softmax=nn.Softmax(dim=-1)
def forward(self, x):
b, c, h, w=x.size()
q=self.gp(self.wq(x)).reshape(b, 1, c//2)
v=self.wv(x).reshape(b, c//2, -1)
z=torch .matmul(nn.softmax(q), v).reshape(b, 1, h, w)
return torch.sigmoid(z)
同理,这里与上文类似,也是类似于通道注意力:
- 使用全局平均池化聚集信息
- 不过这里没有使用 来建模通道间关系,而是直接进行加权,并且在通道维度上进行了求和
- 将上述结果作为注意力
同样地,我们也可以使用经典的 SEnet 来实现这样的操作:
class Spatial_Attention_With_Channel(nn.Module):
def __init__(self, in_ch, ratio=16):
super(Spatial_Attention_With_Channel, self).__init__()
self.global_avg = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Conv2d(in_ch, in_ch//ratio, 1, bias=False)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(in_ch//ratio, in_ch, 1, bias=False)
def forward(self, x):
ave = self.fc2(self.relu(self.fc1(self.global_avg(x))))
atten = (x*ave).sum(axis=1, keepdim=True)
return x*atten
Composition
并列:
顺序:
总结
翻译作 极化 或许不是那么贴切,可能翻译作 偏振 更符合本文的思想
本文的主要贡献是计算注意力的同时,在通道和空间上保持着高分辨率
但是我觉得实际上就是把空间注意力或者通道注意力向后多推了一步,即在计算空间注意力时,使用的是通道注意力的方法,在以往通道注意力得到的 的基础上,进行通道上的求和,将最后结果作为 ;本文的通道注意力也是如此,这样或许能够在计算这二者时,更好地利用其他维度的信息吧。